NAN/머신 러닝
K 평균(K Means) 실습
onddd
2021. 7. 8. 23:37
728x90
K Means / ++ 실습
파이썬 빅 데이터 분석에 가장 많이 활용되는 라이브러리는 Pandas, Numpy, Matplotlib이다.
Numpy : 연산 처리를 용이하게 하기 위해 사용
Pandas : 데이터 포인트를 만들기 위해 사용
Matplotlib : 데이터 시각화에 사용 / seaborn도 함께 사용된다.
실습
from sklearn.cluster import KMeans #sklearn에 포함되어 있는 KMeans 불러오기
# 데이터 마이닝에 필요한 라이브러리 불러오기
import numpy as np
import pandas as pd
import seaborn as sb
import matplotlib.pyplot as plt
%matplotlib inline
# 실습을 위해 준비한 데이터 셋 구성
df = pd.DataFrame(columns=['x','y'])
df.loc[0] = [2,3]
df.loc[1] = [2,11]
df.loc[2] = [2,18]
df.loc[3] = [4,5]
df.loc[4] = [4,7]
df.loc[5] = [5,3]
df.loc[6] = [5,15]
df.loc[7] = [6,6]
df.loc[8] = [6,8]
df.loc[9] = [6,9]
df.loc[10] = [7,2]
df.loc[11] = [7,4]
df.loc[12] = [7,5]
df.loc[13] = [7,17]
df.loc[14] = [7,18]
df.loc[15] = [8,5]
df.loc[16] = [8,4]
df.loc[17] = [9,10]
df.loc[18] = [9,11]
df.loc[19] = [9,15]
df.loc[20] = [9,19]
df.loc[21] = [10,5]
df.loc[22] = [10,8]
df.loc[23] = [10,18]
df.loc[24] = [12,6]
df.loc[25] = [13,5]
df.loc[26] = [14,11]
df.loc[27] = [15,6]
df.loc[28] = [15,18]
df.loc[29] = [18,12]
#정의한 데이터를 확인하기 위해 위에서 30개 확인
df.head(30)
x y
0 2 3
1 2 11
2 2 18
3 4 5
4 4 7
5 5 3
6 5 15
7 6 6
8 6 8
9 6 9
10 7 2
11 7 4
12 7 5
13 7 17
14 7 18
15 8 5
16 8 4
17 9 10
18 9 11
19 9 15
20 9 19
21 10 5
22 10 8
23 10 18
24 12 6
25 13 5
26 14 11
27 15 6
28 15 18
29 18 12
# 불러온 데이터 시각화
sb.lmplot('x','y',data=df, fit_reg=False, scatter_kws={"s":100})
plt.title('K-means Example')
plt.xlabel('x')
plt.ylabel('y')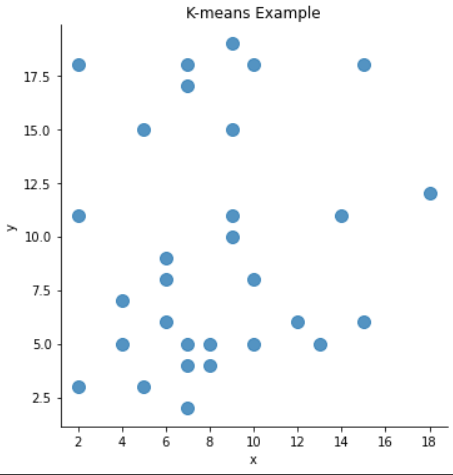
# 시각화까지 이상 없음을 확인 했다면
# Numpy를 사용하여 데이터 연산
points = df.values # DataFrame의 값들을 numpy로 바꿔준다.
kmeans = KMeans(n_clusters=4).fit(points) # 정의한 데이터를 기반으로 kmeans 알고리즘 수행 총 클러스터 4개 설정
kmeans.cluster_centers_ # 각 클러스터들이 중심 위치를 구할 수 있도록 설정
# 성공적으로 클러스터링 구현
array([[ 5.53846154, 5.53846154],
[ 7. , 17.14285714],
[11.14285714, 7.28571429],
[15.66666667, 13.66666667]])
# 기본적으로 별다른 명시가 없다면 자동으로 특정한 위치에서 클러스터링을 수행 할 수 있도록
# 무작위 값을 결정해주는 Kmeans ++ 알고리즘이 작동되기 때문에 실행만 하더라도 클러스터링이 수행된다.
# 무작위 값이 적용되기 때문에 실행 할 때마다 그 값이 변동 된다.
# 각 데이터들이 속한 클러스터 확인하는 방법
kmeans.labels_
array([0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 2, 2, 1, 1, 2,
2, 1, 2, 2, 3, 2, 3, 3], dtype=int32
0~3까지 클러스터에 데이터가 속한것을 확인 할 수 있다.
# 시각화를 위해 'cluster'라는 속성을 만들어준 후 그 값으로는
# 각각의 데이터의 클러스터 id값이 들어가게 만들어준다.
df['cluster'] = kmeans.labels_
df.head(10)
x y cluster
0 2 3 0
1 2 11 0
2 2 18 1
3 4 5 0
4 4 7 0
5 5 3 0
6 5 15 1
7 6 6 0
8 6 8 0
9 6 9 0
# 클러스터링 완료 데이터 시각화
# hue : 특정 속성을 기준으로 색상을 나눔
sb.lmplot('x','y',data=df, fit_reg=False, scatter_kws={"s":150}, hue = "cluster")
plt.title('K-means Example')


https://www.youtube.com/watch?v=sXgQsJLDP8g&list=PLRx0vPvlEmdAbnmLH9yh03cw9UQU_o7PO&index=12